The Foundation for Transparent Tracking in MtO Projects
W. Edwards Deming once stated: “In God we trust. All others must bring data.” In most distressed projects I have worked with, the problem is not that the team lacks data. The problem is that the data they do have cannot be relied upon. Tickets exist, reports are produced, charts are displayed—but the underlying system is often inconsistent, and the numbers, at best, describe a rough mood rather than a reality. However, without trustworthy insights, risk minimization (CORE SPICE Principle #7 and arguably the single most important principle when a project is under stress) will fail.
The underlying data, once it is tied together across the data sources, can deliver quality on the project progress and risks. Unique identifiers, clean taxonomy, clear ownership, consistent closure—those aspects are boring accounting work. But when they are missing, the dashboards above them report numbers that nobody can actually trust.
The good news is that the fix is not particularly sophisticated. It is mostly discipline, applied early and kept consistent. This article walks through what that discipline looks like.
Familiar Symptoms
Most projects under pressure I have encountered share a small catalog of symptoms.
- The same (or at least semantically equivalent) defect is logged several times by four engineers, each with a slightly different label, and nobody notices until the reopen rate starts climbing.
- A feature is declared done, but nobody can point to the specification it was built against.
- A change request gets processed through the defect workflow because that was easier at the time, and three weeks later, the scope has grown without anyone deciding so.
- A system “release” means one thing to engineering, another to testing, and a third to the customer’s purchasing team.
- A supplier tracks its contribution in its own spreadsheet, and the integrator’s project tool has no idea what state the supplier’s deliverables are in.
- The testing team tests based on personal experience because there are no documented specifications traced back to the design or requirements. The “completeness” presumption is a mere intention, not a quantifiable, measurable assessment.
These are some of the symptoms of project distress. More daily syncs, more risk registers, or more “write-only” documents cannot compensate for them. A project can have all of those and still be unable to answer, at any given moment, what exactly a feature is in this project, what counts as a defect, what is in the upcoming release, and who is accountable for each open issue right now.
Four Issue Types
Every trackable thing in an MtO project is an “issue” (or use an equivalent term that encompasses all of the below object types). It is practical to limit the taxonomy to four issue types:
Features are customer-visible functionality or essential quality aspects. They originate from specifications (requirements, design). Each feature has exactly one owner: the Feature Owner (see also the CORE SPICE Accelerator #3: end-to-end responsibility, see here). A Feature Owner is accountable for the definition and delivery of a feature from inception through verification.
Defects (or bugs): Deviations from an approved specification. This is not a philosophical definition; it is a practical one. Without a specification, there is no objective basis for calling something a defect. That is a frequent contractual and organizational problem.
Change Requests: agreed deviations from the approved (“baselined”) scope or specification. They are neither features nor defects, and treating them as either creates predictable trouble. When change requests are handled as defects, the scope expands silently while the quality metrics appear to worsen. When they are treated as features, the burndown inflates, making the project look slower than it really is. Change Request, as a distinct, separate type, avoids both distortions.
Work Items: General tasks. They are everything the team needs to do in order to implement one of the three above. They must always be linked to a feature, a defect, or a change request. An orphan work item with no parent is almost always a sign of either duplication or something that no longer needs to be done.
Often, those “tickets” have different prefixes, so that the nature of a unique object is immediately recognizable. Everything trackable fits into one of them.
The same system needs to serve all contributors, including suppliers. A supplier that maintains its defects in a separate tool with its own classification scheme creates a parallel universe. In such cases, the defect curve often spans only half the project. I prefer to be explicit about this in the Supplier Agreement: suppliers use the project’s issue management tool, with the project’s taxonomy and ID scheme.
Unique Identifiers
Every issue carries a unique identifier with a meaningful prefix, such as FEAT-0142 for features, DEF-1203 for defects, CR-0087 for change requests, or WRK-4561 for work items. The prefix makes the type obvious at a glance, and the number is unique across the project’s full lifecycle. This is one of those basic hygiene items that is easy to underestimate until it is missing, at which point cross-referencing becomes guesswork, and any automated traceability reporting becomes unreliable.
The same principle extends to specifications, test cases, and other artifacts. When a defect references REQ-0033 and TEST-INT-0891, the related trace is unambiguous.
The Small V: A Definition of Done for Every Issue
Every issue—feature, defect, change request, or work item—needs an explicit “Definition of Done.” One pattern that works well across all four types is what I think of as a small V, embedded in the issue itself.
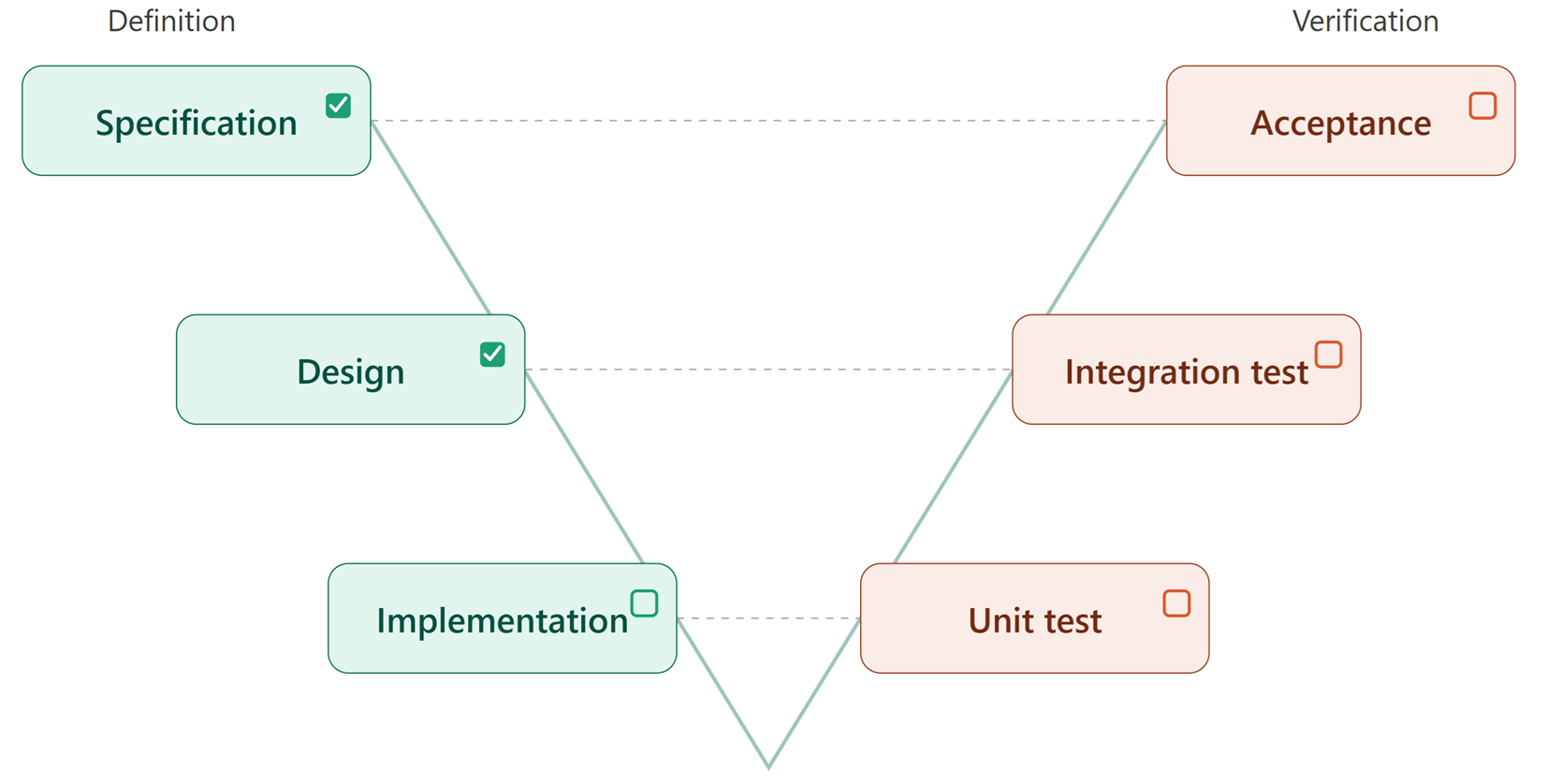
On the left side of the V, the issue is defined: What must be delivered, fixed, changed, or done. On the right side, each item on the left has a corresponding verification.
(Remark: this is a simplified model that does not distinguish between system and software levels. However, I recommend NOT expanding it into system levels (e.g., system requirements, system design, etc.) for practical reasons.)
For a feature, the small V traces from the linked specification down through implementation and back up through integration, system test, and customer acceptance. For a defect, it runs from the specification the defect violates, through the fix, to the verification that the fix holds in the target release. Change Requests follow the same pattern as the features. Work items are negotiable, but the expectation and its verification should be explicitly defined.
That is how the team operationalizes No Task Left Behind (CORE SPICE Accelerator #1). The detailed mechanics—lifecycles, states, review rules—belong in either the Project Approach or the Configuration Management Approach, whichever the team prefers as the home for issue governance.
Release Scope
Every release has a clearly defined scope: which features are included, which defects are resolved, and which change requests are incorporated. In the configuration management literature, this is called a baseline, which is accurate but sometimes sounds a bit ceremonial to engineers. In practice, I find “release scope” a good day-to-day term, while “baseline” remains appropriate in the Configuration Management Approach itself.
Whatever it is called, its absence is costly. Without it, “defect DEF-1203 is fixed” does not actually mean anything unless one can specify which release it is fixed in. The same applies to features. Release scope is what the customer is comparing against at delivery.
The discipline is not complicated: each release has a named, frozen scope. Every known defect carries an estimate and a target release, or it is unplanned work dressed up as planned work. Changes to the scope after freeze are themselves change requests and flow through the normal change request workflow. The Project Lead, supported by the Configuration Manager and the TCC, maintains scope consistency.
Effort Estimation
Effort estimation has a reputation for being annoying. It is, but it is also one of the most useful disciplines a project team can adopt—not because the numbers are precise, but because the act of estimating forces the team to think thoroughly about each new/modified issue before it enters a release scope. In a way, “the plan is nothing—the planning is everything.” The real value of the planning activity is gaining a thorough understanding of the complexity and risks of each new issue.
A simple three-bucket scale works well for most MtO projects I have seen:
- S: about 4 hours (a working morning)
- M: about 2 days
- L: larger than M
“S” issue is something that one engineer can complete in a focused half-day.
“M” is a two-day commitment, often with a small handoff.
“L” is everything beyond that.
More detailed estimates are usually not meaningful because of the uncertainty inherent in each set of issues.
Also, “L” comes with a specific rule. Whenever an “L” issue appears, the team’s first response should be to break it down into smaller “S” or “M” issues, each with its own Definition of Done, owner, and traceability. Most “L” issues, on closer inspection, decompose naturally. But not all of them do. Some tasks—a complex system integration, a regulatory submission, a particular safety-critical algorithm—are genuinely atomic. Forcing artificial decomposition produces a fake structure that hides the real risk rather than reveals it.
When an “L” issue cannot be meaningfully broken down, the team should treat its size as the actual problem to manage. Such treatment achieves two things: a) it helps prioritize at or near the top of the release backlog, and b) it is assigned to one of the most highly skilled available owners. Usually, junior engineers cannot effectively handle that level of uncertainty inside a fixed-budget MtO contract; senior engineers can. This is Risk Minimization (CORE SPICE Principle #7) made operational at the issue level.
A Note on Units
Estimates in CORE SPICE projects are expressed in real, calendar-aligned units—hours and days, not “story points” or other abstractions. Story points have their defenders, and there is a legitimate argument that they decouple estimation from individual capacity, so a junior and a senior engineer can agree on a relative size without arguing about who is faster. That argument is acceptable in open-ended R&D projects, but it does not survive contact with MtO reality. The customer’s contract is usually in working days or weeks. The Project Lead needs to know whether the release will land on time, in days, not in abstract points. In reality, story points must almost always be translated back to days anyway, which makes them an extra layer of abstraction with no added value to the team’s effectiveness.
Estimation applies to every issue type, not just features. Defects, change requests, and work items all carry estimates and target releases—or they are unplanned work masquerading as planned.
Traceability: The Minimum That Matters
Traceability is one of those topics that tends to get overblown in strongly regulated projects, where the tendency is to trace everything to everything and discover six months later that nobody is actually reading the traceability matrix. A smaller, deliberate set of traces is more useful and much easier to maintain:
- From specification (requirement, design) to feature.
- From specification (requirement, design) to test case.
- From test case to one or more test runs.
- From each test run to its result data.
- From any defect back to the test run, the test case, and the specification it violates (and, consequently, the associated feature).
These traces are sufficient to make the small V auditable for every issue, and to make the defect curve meaningful at release boundaries. The details of what is traced, how, and by whom belong in the Traceability Approach.
Living Documents and Baselined Documents (a.k.a. “Artifacts”)
Not every project artifact is “frozen.” Specifications—requirements, design, interface definitions—are baselined. They are fixed at a version, associated with a specific release, and changed only through a deliberate revision. In contrast, the CORE SPICE Approach documents—the Issue Management Approach, the Configuration Management Approach, the Project Approach, and others—are, by design, living documents. They evolve as the team learns what works and what does not. All artifacts must have clearly named owners and visible status, but the mechanics differ: a living document is versioned without being frozen; a baselined document is frozen by design.
Artifacts in distressed projects usually have at least one of the following flaws: Either the Approaches are frozen into bureaucratic immutability and become useless (“write-only”), or the specifications are never frozen at all, leaving them unreferenceable. Both failures are avoidable once the distinction is explicit and articulated in one of the corresponding Approaches.
Two Views, One System
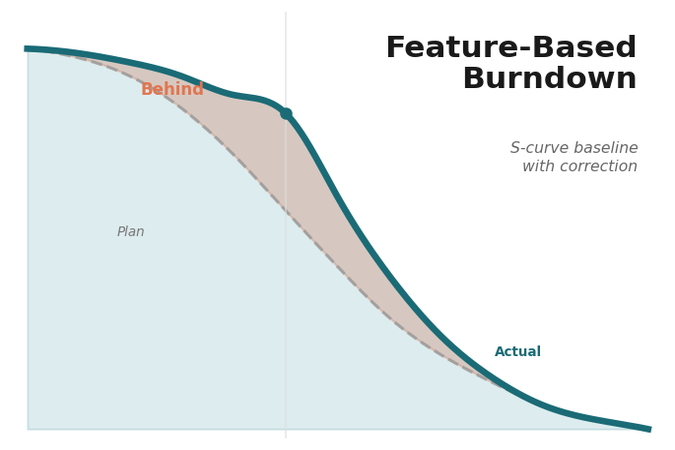
A recurring question from customers is whether to display features and defects on a single combined burndown chart or on two separate ones. This is essentially a presentation choice, and I recommend treating it as such.
Keeping features and defects on separate charts makes sense. Feature closure is a steady, human-paced activity; defect closure arrives in waves, peaking around integration and release. Mixing them on a single chart obscures the dynamics of both. Externally, if the customer’s key stakeholder prefers a combined view, it is straightforward to derive one from the same underlying data. The two views are not in conflict. One serves operational needs, the other communication, and both are automated from the same issue management system.
A Simple KPI Set
Once the foundation is in place, a small set of KPIs is enough to give the Project Lead and the key stakeholders a clear read on progress, risk, and where to intervene:
- Feature closure rate and projected release completion can be visualized in the feature burndown.
- Critical defect backlog and its trend can be visualized as a defect curve.
- Open change requests and their scope impact can be visualized similarly to the features.
- Reopen rate. This metric is typically used for defects.
- Release scope readiness shows the next release has a frozen, deliverable scope. That can be integrated into the overall release plan (from inception to SOP).
Those metrics should be automatically generated daily. This is what the Project Lead reads to see progress and risk. It is also what the customer sees, and what builds or erodes trust over time. Further KPIs are optional. When a project starts tracking dozens of KPIs, it is usually because the underlying data cannot quite be trusted. So be careful when adding KPIs.
Radical Transparency
A unified issue system, properly used, produces something that distressed projects almost never have: an honest, shared view of reality. Every issue is visible. Every status is current. Every estimate is in real units. Every release scope is named. Every defect can be traced back to its specification. The Project Lead, the team, the suppliers, and the customer are looking at the same data, in the same system, at the same time. There is no parallel universe. There is no “internal” version of the truth and an “external” version for the steering committee. There must be a single source of truth for everyone.
This may appear uncomfortable at first, especially for teams accustomed to managing the customer’s perception by curating what they see. But it is also liberating. The team stops spending energy on impression management and starts spending it on the actual work. The customer stops asking suspicious questions because nothing is being hidden from them. The relationship shifts from adversarial to collaborative—not because everyone became more reasonable, but because the data made obfuscation impossible.
Radical transparency is also, in my experience, the single strongest predictor of whether a distressed project will recover. Teams that hide their problems cannot fix them.
Automation and the Project Tool Engineer
KPIs should not be maintained by hand. It should be automated, and the role responsible for that automation is the Project Tool Engineer. This project role should be introduced early (in line with CORE SPICE Accelerator #5 “Automate Everything” and Principle #12 (Automated Traceability)). This role designs and maintains the automations that generate the burndown, defect curve, KPI set, traceability reports, and release scope view.
When the role is missing or underresourced, engineers end up spending valuable time on manual reporting—or even worse, not at all. In such cases, teams work in expensive, wasteful silos, which is an anti-pattern that is expensive, error-prone, and demoralizing. In 2026, there is, in most cases, no good reason for manual reporting. The Project Tool Engineer role enables the rest of the foundation to pay for itself.
Discipline, Not Bureaucracy
A well-structured project management system may appear bureaucratic: more prefixes, more closure criteria, more fields to fill in, more structure around what engineers would prefer to simply get stuff done. Senior engineers have seen enough process-heavy initiatives fail to recognize the pattern, and their skepticism is a healthy reaction to their past experience.
The difference is that the strategy described in this article is both uncompromising and super simple. The “plumbing” described above is not compliance theater; it is the mechanism that replaces compliance theater. With honest data in place, the team stops being judged by numbers nobody trusts and starts showing—to management, to the customer, to each other—what is actually true. That is the opposite of bureaucracy. It is Merit Over Bureaucracy (CORE SPICE Principle #11) made operational.
Skepticism can, in my view, only be resolved by demonstrating the practical value of such an integrated project management system. In my experience, adoption rarely comes from the initial explanation. You cannot “convince” professionals by merely postulating a quality framework. It comes from the first honest burndown or defect curve that the team recognizes as the truth they already knew anecdotally. Once that moment arrives, the system becomes a Formula 1 car rather than a mule carriage.
Conclusion
Deming’s observation applies universally: no data, no insights; no insights, no real risk minimization.
The three articles of this series describe a complete recovery dashboard:
- The feature burndown tells the team whether delivery is on track.
- The defect curve indicates whether quality is on track.
- The unified issue system ensures that the data feeding both charts is honest.
With the simple taxonomy—four issue types, unique identifiers, one system including suppliers, a Definition of Done for every issue, a clearly defined release scope, living and baselined documents properly separated, and a handful of KPIs automated—the project team can see what is actually happening in their project.
That is the precondition for minimizing risk, for the radical Transparency that distinguishes recovering projects from sinking ones, for a trusting customer relationship, and ultimately for a successful SOP.
Where to Start
For a team starting a new project, the first Approach to draft is the Issue Management Approach. Note that the Project Approach is also created at the same time. Still, the Project Approach remains a working, living document for a long time—actually, until all other Approaches have been fully established. Nevertheless, the Issue Management Approach is the foundation on which everything else depends, and the one that repays the investment the fastest—often within a single release cycle. The Configuration Management Approach and the Traceability Approach follow naturally once the taxonomy and identifiers are agreed upon.
For a team already “in flight,” the honest answer is less tidy, but the same three Approaches remain the right starting point. Retrofitting costs more than a greenfield setup, but continuing without a foundation costs even more.
References
- Feature-Based Project Tracking — projectcrunch.com/feature-based-project-tracking-how-to-regain-control-in-distressed-mto-projects/
- The Defect Curve — projectcrunch.com/the-defect-curve-a-key-factor-in-turning-around-distressed-mto-projects/
- CORE SPICE Coaching Concept — projectcrunch.com/core-spice-coaching-concept/

I am a project manager (Project Manager Professional, PMP), a Project Coach, a management consultant, and a book author. I have worked in the software industry since 1992 and as a manager consultant since 1998. Please visit my United Mentors home page for more details. Contact me on LinkedIn for direct feedback on my articles.